
Frederic Berst guides a team that builds libraries. Not the kind that hold books, but the kind that contain millions of chemicals that could someday become drugs. His team’s work, performed at the chemistry bench, is making it possible for drug hunters at Novartis to reimagine the way they search for new medicines for cancer and other diseases.
There’s a strong need for new ways to find cancer drugs because, for some cancers, the old ways haven’t worked. Despite advances in cancer treatment over the last four decades, survival rates remain low for diseases like pancreatic and colorectal cancer. Only about 7% of people diagnosed with pancreatic cancer survive for five years.
Researchers have tried for decades to find drugs that interrupt the molecular mechanisms that drive these cancers. Their universal failure has led to the notion that certain targets are simply “undruggable.”
But researchers at Novartis, like Johannes Ottl, a biologist searching for new cancer drug leads, believe otherwise: Where old drug discovery methods have failed, new ones may succeed. So they have launched a range of drug discovery efforts using new technologies such as Berst’s DNA-encoded libraries, which provide a fast and thorough means of finding compounds that bind to a cancer-driving molecular target. The researchers hope this effort and others in parallel will give them the toehold they need to discover completely new ways of disrupting these cancers and meet their ultimate goal of bringing more effective therapies to the patients who need them.
Getting a grip
One technique for discovering a lead on a potential drug for a given target is to use high-throughput screening methods. Put the target – usually a protein that acts as a molecular machine – in a grid of wells on a plate, add different candidate drug compounds to each well, and see what happens.
Seeing what happens typically involves a biochemical readout, a little like using a test strip to see if a swimming pool contains enough chlorine. Instead of searching for chlorine, drug hunters might look for the presence of a substance their molecular machine creates or breaks down in the process of driving cancer. If a compound interrupts that mechanism, the test detects the change and the compound becomes a drug candidate. Using high-tech robotics, precision measurements and extremely dense grids of miniaturized wells, a million compounds can be screened rapidly.
But so-called undruggable targets aren’t so straightforward in the way they drive cancer. “They lack the readout,” says Ottl, an expert on DNA-encoded libraries and a member of the Chemical Biology and Therapeutics team at the Novartis Institutes for BioMedical Research (NIBR).
DNA-encoded libraries, however, provide exactly that robust, direct readout. They give researchers a quick way to tell if a compound chemically binds to a target.
The same way a mountain climber might test a range of footwear to see which grip fits best into rocky crags or icy cracks, a drug hunter will test compounds with different chemical properties to see which fits best into the chemical space of a given protein target. “This is the beauty of a DNA-encoded library,” says Simona Cotesta, a chemist in NIBR’s Global Discovery Chemistry group who is focused on applying DNA-encoded libraries to oncology drug discovery. “It’s a large collection of chemicals with lots of different features that we can explore to see what works with a given target.”

A hit – the discovery of a compound that binds to the target – is what researchers need to get started on drug discovery. From there, chemists work to understand how the compound binds to the target and what opportunities there might be for leveraging that tether to interrupt the target’s activity.
For instance, the compound might interrupt the protein’s cancer-driving machinery. If not, the compound could still potentially be used to mark the protein for degradation by the cell’s garbage collector, taking the protein out of action. Or it could be used as a means to glue the protein to something else that interrupts its machinery. “The first step is finding the hit. You have to see if you can attribute function to it later,” says Saskia Brachmann, a NIBR researcher searching for new oncology drug leads.
Finding the needle in the haystack
Scientists like Ottl and Berst, of NIBR’s Global Discovery Chemistry group, create DNA-encoded compound libraries by combining groups of chemical building blocks together into larger compounds. Each building block is selected based on desired chemical properties, such as molecular diversity or whether it fits into a chemical space relevant to the target of interest.
Every building block is assigned a unique label, akin to a barcode. In turn, each compound formed by a combination of building blocks has a barcode composed from its building blocks' codes. Rather than a series of parallel lines forming a standard barcode on a paper label, however, the barcodes in a DNA-encoded library are strands of unique DNA sequences.
The approach enables chemists to create staggeringly large libraries. By selecting, say, 200 building blocks of one type, 200 of another, and 500 of yet another – with the molecules of each type designed to react with one another and join together – chemists could synthesize a library of 20 million compounds without having to synthesize each chemical individually.
The current Novartis chemistry archive, compiled over decades, contains about 1.5 million compounds. Since the work on DNA-encoded libraries at Novartis began in 2015, the team has designed and built more than a dozen libraries that together contain approximately over a billion compounds, expanding by a thousand-fold the range of chemicals they can explore as possible drug candidates.
But sheer volume isn’t the only consideration, says Ottl. “Thoughtful design is required to create high-quality libraries of compounds that have potential value for further investigation.”
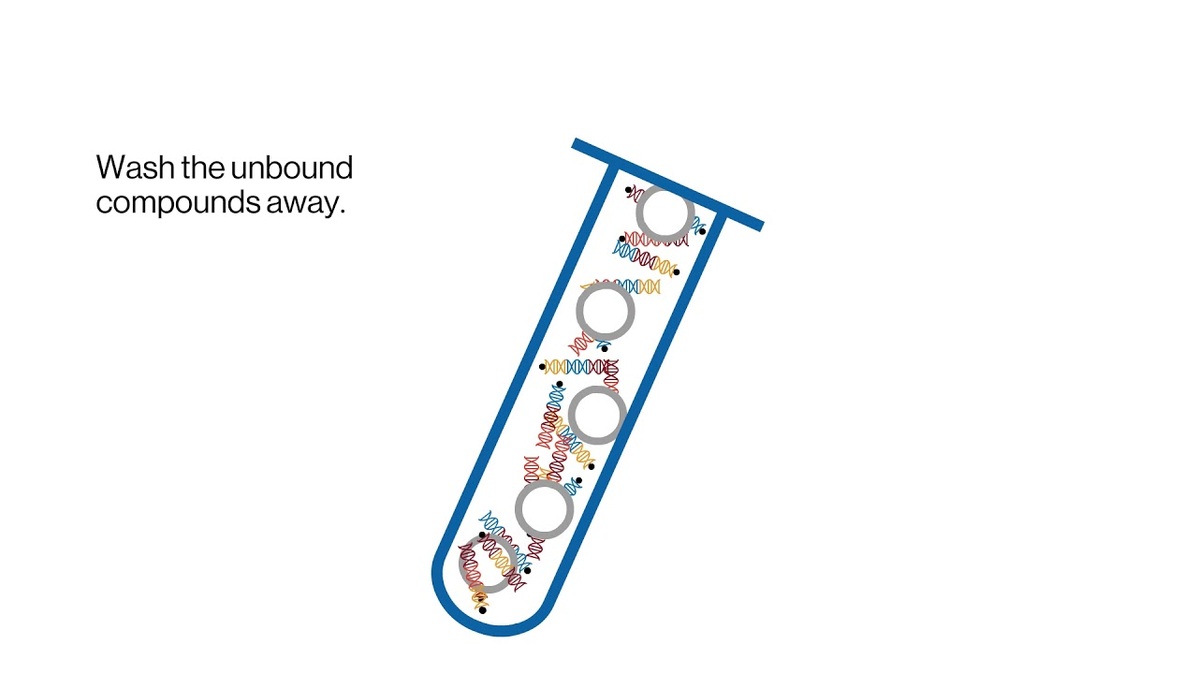
The contents of an entire DNA-encoded library can be placed into a single test tube. Screening happens all at once by adding the protein target of interest to the test tube. Researchers find hits by rinsing away any compounds that don't bind efficiently to the target. They then "read" the barcodes of the remaining bound compounds using molecular biology and DNA sequencing. “This gives us a way to find the needle in the haystack and a starting point for drug discovery,” says Ottl.
In parallel, Brachmann’s team is trying the opposite approach: to build functional readouts into the system from the beginning. While this is a more involved method and requires distinct readouts for each project, much of the learning about how the compound could act as a drug is already done. “DNA-encoded libraries are one of several ways we are trying to move forward,” she says.
Main image: Biologist Johannes Ottl and chemist Frederic Berst work side-by-side to craft DNA-encoded libraries to facilitate the discovery of drugs for hard-to-drug targets. Image by Christian Jaeggi.
Learn how Novartis researchers are using DNA-encoded libraries to discover new drugs. #drugdiscovery


